

WHY do people think everything needs to be cropped to hell just to fit on their phone. The screen rotates. Just twist it around ya lazy bastards.
Anyhow, here’s a link to the full size video that isn’t pointlessly cut down by 75%: https://www.youtube.com/watch?v=QThaHpkFVzw
deleted by creator
This video comes from the official Internet Archive TikTok page. I’m not sure if that makes it better or worse lol!
https://www.tiktok.com/@weareinternetarchive/video/7329355972428696874
Explains its existence at least.
The video contains all necessary information and you don’t need to turn your phone. I don’t see a problem here.
You could say the same thing about a video recording of a pc monitor. Yeah all the necessary stuff is there but you also lose a lot may it be quality or just more pixels which give greater context to the video by showing more of the actual recording
With the full size recording you can see more of the machine which is part of the main subject so it’s not just meaningless data/context either
Ok. Good luck with that.
Here is an alternative Piped link(s):
https://www.piped.video/watch?v=QThaHpkFVzw
Piped is a privacy-respecting open-source alternative frontend to YouTube.
I’m open-source; check me out at GitHub.
I’m with you but it’s not about being lazy, just like shit audio being on most videos these days this is yet another symptom of tiktok bullshit.
Videos with shit sounds get more traction and tiktok wants every video to be scrollable without havin to turn your phone and shit so the result is trash like this getting pumped out which ruins the actual video content
deleted by creator
Why care? In a second I’ll leave this video and never think of it again. The key point is conveyed, and we are all done.
Because someone went out of their way to mutilate a video for no reason, so I’m gonna go out of my way to make it right. Just because you can’t be bothered to care doesn’t mean everyone else is just like you.
This isn’t a “significant” video. By any standard. Digest the information and move on. Doing otherwise is fist fighting the waves on the beach.
Most importantly, the purpose and message of the video is conveyed.
Thankfully, you don’t get to decide what other people consider “significant”. I’ll spend my time how I want, thanks.
Literally name any metric or qualifier of objective nature.
Lol, no. You don’t get to debate me into not valuing something. Deal with it.
You deal. You’re the one having a this about a fully informative short clip.
You clearly only have subjective value positions to argue from, and can’t meaningfully refute my points.
There’s no problem enjoying content the way you do. There’s a problem getting angry about a video that literally does it’s job
Wouldn’t it be great to have it dynamic based on device?
Anyway, everyone’ll have to get off our lawn.
For the average world netizen…
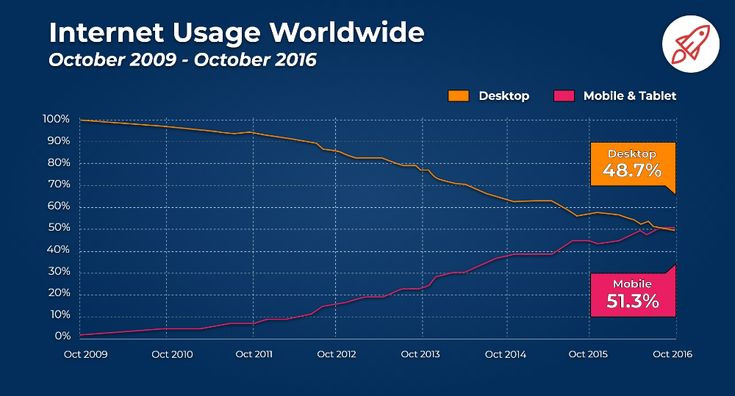
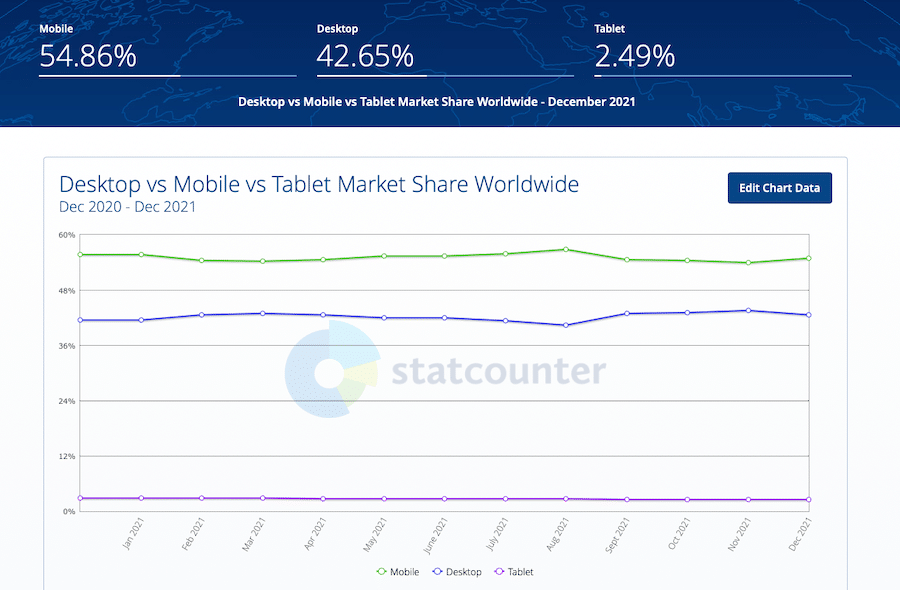
…OP’s is the desirable format.
Here I am on my phone. I do not desire this format. And nothing you have posted suggests that anyone wants this format.
All it shows is device, not preference.
Anytime something is recorded wide screen my wish is that it remains in that format, regardless of platform I am on.
If I’m on my phone it takes less than half a second to rotate my screen and view as intended, on my desktop I can’t do that.
Also in this case quite a bit of the original was lost, seeing the YouTube version is much better.
Diagonal video is obviously the superior format:
Why stop at video!
You don’t understand the data. That data has nothing to do with what video format people prefer.
Looks like two pages at a time to me.
each piece of paper is a page, since they do the front of one and the back of another at the same time, it’s one page total…
One Sheet, Two Pages A sheet of paper has two sides. Each side is considered one page. So a single sheet of unfolded paper is two pages.
One sheet, two leaves, four pages.
Is that why each sheet of paper has the same page number on both sides in books? Oh wait they don’t.
;)
deleted by creator
Gotem
c/theydidthemath /s
Thank you, Internet Archive.
Please remember to make a donation to the Internet Archive for the invaluable work they do!
We so appreciate your efforts, but ya’ll need more funding so you can start working smart and not hard. From the looks of things, I see no reason why page flips can’t be automated there.
I just made a donation. Please use it to save this poor woman from the tedious task you’ve shown us today.
I think this is one of those things that seems like it should be easy to automate, but actually has lots of hidden complexity.
They probably don’t use this to scan commonly available books, because for those you can just cut the spine off the book and scan the pages in a regular scanner.
This is likely used for books that need to be preserved and can’t be damaged during the scanning process.
How do you make a machine that will always turn exactly one page and never tear a page, while adapting for different page sizes and thicknesses, and avoiding the static charge that can make pages stick together? All for less money than it costs to pay people to operate this machine.
Iirc they did experience with automation before and did get it to copy well…
But like you said, it would damage books pretty frequently. That’s not what you’d want for old and fragile materials which are rather irreplaceable.
Vacuum!
We should start doing charity style TV ads.
“You, too, can help us build page turners and save the lives of dozens of archivists. Just £2 a month will allow Margaret to finally rest.”
Man I got some friends who are archivists, and they’d love that shit lol.
They love their field, but it’s a lot of mind-numbing work
I’d just use a bandsaw to cut off the spine and stick it in a document feeder.
Leave that poor woman alone you psycho!
If the book is not that easily available (old, rare), it’s much better to keep it intact.
This must be how you get “binders full of women”
Wow that seems painfully slow/tedious. Why isn’t it automatized? I think I saw a robot do like 20 pages a second on a yt some years ago.
Do you remember the results of those speed scans? Crooked pages, parts of the document cut off, blurry scans, etc.
It was a lazy method that resulted in a lot of junk data.
I think this is what I saw. Not quite 20 pages/s hahah and also a different method.
Google have digitised a lot of books using some more advanced tech, though they started out with something a little like this.
What happened to that in the end? I heard they wanted to digitize the worlds books and then it just petered out at some point and heard nothing about it. Did they continue or was it spun to Internet Archive to do?
My understanding is the project led into Google Books. Google fought many legal cases and ultimately won but their enthusiasm to scan more books seems to have waned. Google basically convinced judges that by only letting people see a few pages, it fell under fair use, but then that meant you didn’t get a giant library because you couldn’t read the whole book.
There’s an article about it here: https://www.edsurge.com/news/2017-08-10-what-happened-to-google-s-effort-to-scan-millions-of-university-library-books
Also see https://www.hathitrust.org/about/ which is mentioned in the article.
That would be interesting to see!
This is probably the method that gives you the best quality (deskewing, lighting) without cutting the back of the book and feeding it into a scanner. (AFAIK)
I saw a book scanner similar to this one that used a vacuum to turn pages but otherwise same principle.
There are DIY tutorials for that for those interested: https://www.diybookscanner.org/en/intro.html
This is awesome, thanks!
There should be a law that should any book go out of print, to be digitized and made available online. Publishers shouldn’t dictate which books are allowed to be consumed once they allow it out of print when digital versions cost next to nothing to make available for a nominal price.
That goes for authors owning the copyright, as well.
And limited to 25 years. This 100 years is bull shit.
Do you really work there?
If so… We love you.
Today I learned that firefox doesn’t like to play certain types of mp4 files. I also learned that you can copy a video link and paste it into VLC media player and it will play!
Watching these books being archived is amazing, I would love to do this!
I also learned that you can copy a video link and paste it into VLC media player and it will play!
You can also use this trick to download YouTube videos without the need of a 3rd party website!
-
Copy the URL of the YouTube video you wanna download
-
VLC / Media / Open network stream… And paste your URL
-
Once the video has opened, Tools / Media Information
-
Copy the URL in the “Location” field and paste it into your web browser, you should have the option to save the video
It’s a couple of steps but once you memorize what you need to do it’s a million times faster (and I’d wager equally times as private) than finding one of those websites to give you a link.
or just use youtube-dl
edit: here’s an electron gui wrapper: youtube-dl-guiNeat! I figured out accidentally that you don’t have to do step 2, you can just open VLC and ctrl+v!
I am downloading a test video now, thanks that’s very cool!
Nice, step 3 can also be accomplished with CTRL-I, at least on the windows version of VLC
Amazing! I showed my husband last night, he was equally amazed. :)
-
MP4 is just a container, the specific audio/video streams can be one of several different codecs, and if you don’t have the codec used it won’t work. If you can identify the encoding you could probably just download a codec and be good to go.
Edit: for this video the video codec is
Codec: MPEG-H Part2/HEVC (H.265) (hvc1)
and audio codec is
Codec: MPEG AAC Audio (mp4a)
The more I read about this, the more confused I am! Near as I can tell, Mozilla refuses to support H.265 because it is “encumbered by patents”. Is that right?
https://developer.mozilla.org/en-US/docs/Web/Media/Formats/Video_codecs#hevc_h.265
There are a few other places that mention the same… and I don’t know of a reputable place to download codecs.
However people in this thread say they are viewing this video in Firefox just fine! o_O
Edit: I downloaded the HEVC codec from the Microsoft store and it has had no effect. (Feel no obligation to reply, at this point I am just lost!)
Yeah, firefox doesnt support H.265 it looks like from some googling. Not exactly sure how other people are getting it to work, but it does look like there’s some extensions for firefox to toss the media streams to VLC instead, that could work for you.
Today I learned that firefox doesn’t like to play certain types of mp4 files.
Probably missing a few dll’s or something, works fine for me.
I tried googling and came up with nothing other than articles suggesting I delete my cookies and update firefox. If you know what dll’s I should check please let me know! :)
Depends on your OS and the alignment of Venus with the moon. For Linux, there’s Archwiki, sacrifice a
lambfew bytes for good measure.It’s usually something with media acceleration not set up yet. I believe i had to install the amdgpu-32bit driver first, before it worked? (oc only if you have amdgpu)
Kids in university watching this: 😯
Automatic page turners are unreliable?
May I bring my son to visit? I know it’s typically only for events. He will crack up at the statues and be underwhelmed by the two racks containing the entire Internet.
How do you reliably turn pages that fast without accidentally grabbing two pages and skipping? Im impressed!
Meditation practice helps with this kind of thing.
That and your king fu skills as you travel the west in the search for your family’s roots.
It definitely improves your kung fu. But meditation really only activates super small refinements. You gotta build the kung fu before there’s anything for the meditation to sharpen.
Basically it increases the resolution of your sensory streams. I mean, that’s the lowest-level effect of all that time spent focusing on the streaming present.
Tacky-Finger.
I don’t often donate since it’s mostly in USD, but internet archive was one of the few that I did.














