

1·
9 months agoI meant smaller models profit more from the stable perplexity in a long prompt with the recently released code changes. Because the paper(s) mention that some of these changes do not require further fine-tuning, we can use small models in a text that is longer than their context size.


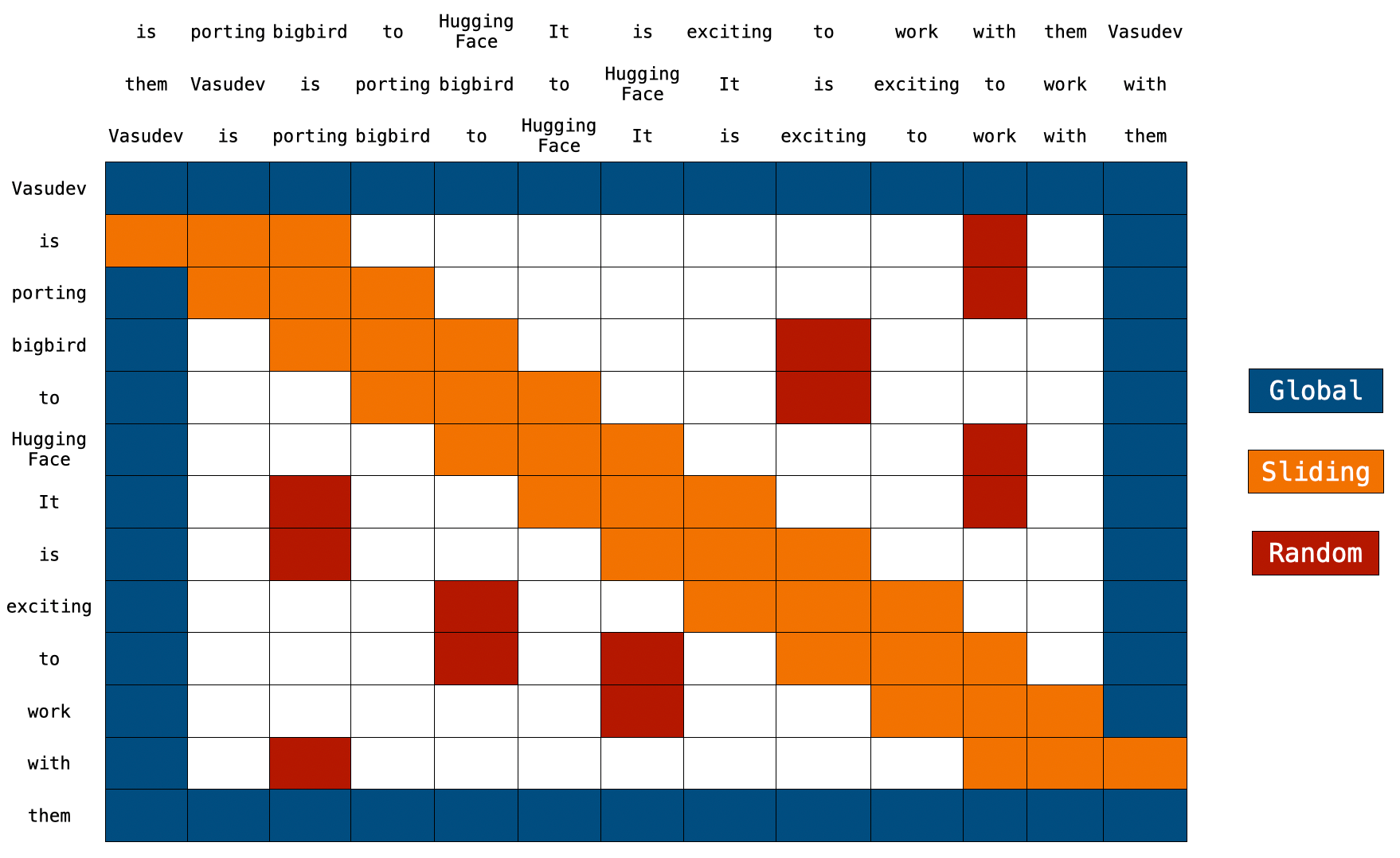

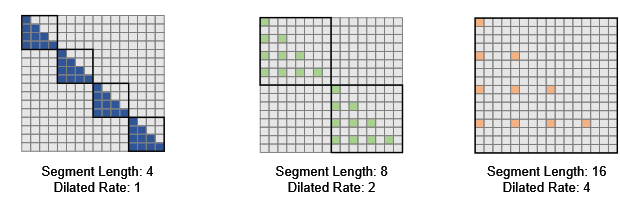






You can download 7B, 13B Q_8 models for such gpu. 30B Q_2 models would probably run out of memory.
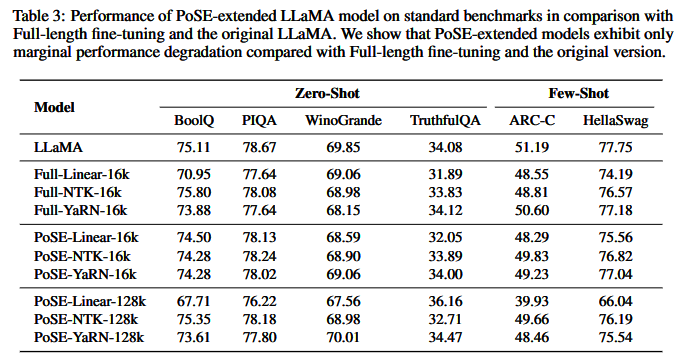
This shows that larger models have lower perplexity (i.e. more coherent). You can run conversational models, but not those with infinite knowledge base.
Most of the paid services that provide open-source models use 13B models (for $15 per month); you can run those for free on your card.
Someone else needs to recommend a tool to run models locally.